Morgan英文面试准备
前言
虽然Morgan面试这事儿已经翻篇啦,把之前自己为英文面试做准备的草稿整理一下传上来。提前说明:1)这只是草稿,所以有的是英文句子,有的是英文关键词,有的是中文,有的是博客链接。2)由于本人比较菜,之前也没正儿八经准备过408/八股这类,所以可能有些很简单的问题或者很差劲很一般的回答。3)本博客没有做教程的目的,主要是为了记录。如果能给他人起一点参考则更好。4)所有的题目主要是针对网络搜集的摩根的面经而作的准备,很可能对面试其他外企没有帮助。
正文
数据库相关
SQL Injection
Concept:
an attack method, utilize programmers’ negligence to achieve to login without account, or even temper the DB
Example
1 | |
How to avoid
variable should has the fixed type + check whether match the types and formats of variable
filter special symbols
- binding variables, using pre-compiled statements
SQL JOIN
Inner Join: Returns all rows when there isat least one match in both tables
Left Join: Return all rows from the left table, and the matched rows from the right table
- Right Join: Return all rows from the right table,and the matched rows from the left table
- Full Join: Return all rows when there is amatch in one of the tables
ACID of database
- Atomic (if the change is committed, ithappens in onefell swoop; you can never see “half a change”)
- Consistent (the change can only happen ifthe new stateof the system will be valid; any attempt to commit an invalidchange will fail,leaving the system in its previous valid state)
- Isolated (no-one else sees any part of thetransaction until it’s committed)
- Durable (once the change has happened - ifthe systemsays the transaction has been committed, the client doesn’t need toworry about”flushing” the system to make the change”stick”)
Transaction Concurrency Problems
concept of transaction: A transaction is a unit of work that you want to treat as “a whole”. It has to either happen in full, or not at all.
problems
miss modification:更新操作被另外一个事务的更新操作替换
dirty read:在不同的事务下,当前事务T2可以读到另外事务T1未提交的数据。(T1 rollback)
unrepeatable read:在一个事务内多次读取同一数据,未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。
phantom read幻读:读取范围过程中插入新范围
Solution
adding lock(但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。)
- exclusive lock
- shared lock
- intention lock
isolation level:
- read uncommitted (MVCC)
- read committed (MVCC)
- repeatable read
- serializable (implement by adding lock)
数据库存储过程
存储过程是一些预编译的SQL语句。更加直白的理解:存储过程可以说是一个记录集,它是由一些下-SQL语句组成的代码块,这些T-SQL语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后再给这个代码块取一个名字,在用到这个功能的时候调用他就行了。
- 存储过程是一个预编译的代码块,执行效率比较高
- 一个存储过程替代大量T_SQL语句,可以降低网络通信量,提高通信速率
- 可以一定程度上确保数据安全
关系型数据库和非关系型数据库
关系型数据库通过外键关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
- 优点:
- 易于维护:都是使用表结构,格式一致;
- 方便:SQL语言通用,可用于复杂查询;
- 复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
- 缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 固定的表结构,灵活度稍欠;
- 高并发读写需求,传统关系型数据库来说,硬盘1/0是一个很大的瓶颈。
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
- 优点:
- 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
- 高扩展性;
- 成本低:nosql数据库部署简单,基本都是开源软件。
- 缺点:
- 不提供sql支持,学习和使用成本较高;
- 无事务处理;
- 数据结构相对复杂,复杂查询方面稍欠。
非关系型数据库的分类和比较:
- 文档型
- key-value型
- 列式数据库
- 图形数据库
Clustered Index and Unclustered Index
聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。
操作系统相关
Thread and process
features
Thread: run in shared memory space; easier tocreate and terminate; lightweight; possess fewer resources; faster task-switching; data sharing with otherthread; care synchronization overhead of shared data;
Process: separate memory space; heavyweight; possess more resources; independent of each other; consist of mutipule thread
Communication Method
参考链接
linux 常用命令
concurrency and parallelism
The difference between concurrency and parallelism lies in the number of events handled. Concurrency means that you can handle multiple simultaneous events, and parallelism means that you can handle two events at the same time.
For example,Concurrency is when multiple tasks use the CPU alternately, or only one task is running at a time. Parallelism is when multiple tasks are running simultaneously
计算机网络相关
TCP & UDP

Java相关
Difference between Java and C++
Five words to conclude
- C++: object-oriented, Platform or Machine Independent/ Portable, Compiler-Based, Speed, DMA (Dynamic Memory Allocation)
- Java: object-oriented, interpreter-based, Robust, Platform Independent/ Portable, Multithreaded, high performance, distributed,
Difference
Although Java and C++ are both object-oriented languages that support encapsulation, inheritance, and polymorphism, there are a number of differences between them. Java does not provide pointers for direct memory access, which makes program memory safer Java classes are mono-inherited, C++ supports multiple inheritance; although Java classes cannot be multi-inherited, interfaces can be multi-inherited. Java has an automatic memory management garbage collection mechanism (GC), which does not require the programmer to release useless memory manually. C ++ supports both method overloading and operator overloading, but Java only supports method overloading (operator overloading adds complexity, which is inconsistent with Java’s original design philosophy).
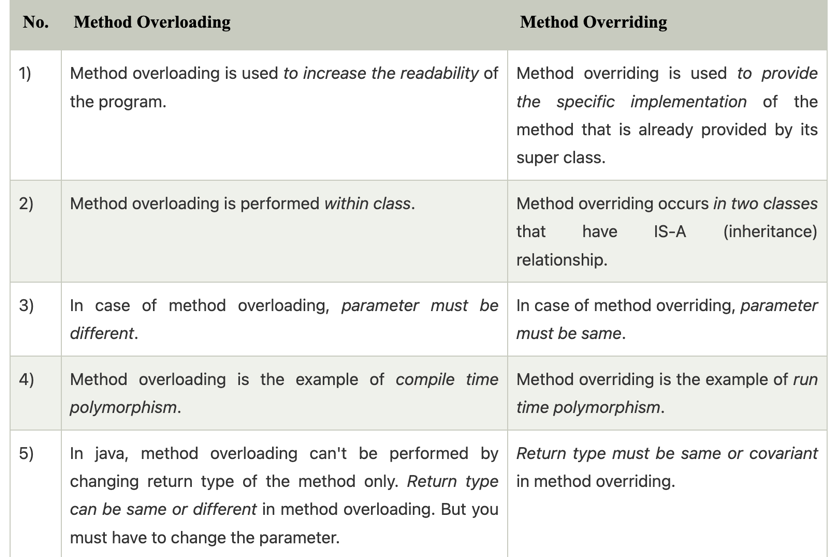
Override and overload
- overload: polymophism, different methods in a class (which have different type and number of parameters)
- override: subclass inherit parent class and make some difference; and if use the original method in parent class —> use Super
线程安全的数据结构/函数:
HashTable,ConcurrentHashMap,CopyOnWriteArrayList,CopyOnWriteArraySet,ConcurrentLinkedQueue,Vector,StringBuffer
Objective-oriented Programming
It is to model and abstract the problem solving methods into objects. Then giving properties and methods to these objects and letting the objects perform these operations.
features
Polymorphism: Polymorphism is the ability (in programming)to present the same interface for differing underlying forms (data types). Polymorphism is when you can treat an object as a generic version of something, but when you access it, the code determines which exact type it is and calls the associated code
Encapsulation: Data and data-based operations are encapsulated using abstract data types so that they form an indivisible, independent entity. The data is protected inside the abstract data type, hiding the internal details as much as possible and keeping only some external interfaces to connect it to the outside. The user does not need to care about the internal details of the object, but can access the object through the interfaces provided by the object to the outside.
inheritance: allow us to define a class in terms of another class, which makes it easier to create and maintain an application. This also provides an opportunity to reuse the code functionality and fast implementation time.
advantages
Easy to maintain, expand, euse, can design a low-coupling system, easy to expand, reuse.
网上2022摩根面经中的2个题目
how to desian a system like taobao
- first: MVC(Model View Controller) design a web —> develop front-end (i.e. html5 css3 javascript jquery vue) + back-end(including database) (some framwork, like Springboot)
- database can be uploaded to cloud servers
- consider high-concurrency:
- divide service, a database for a service
- cache , can use Redis, 高并发场景,大多读多写少,可以在数据库和缓存里都写一份,然后读时大量走缓存。
- mq for 异步 Synchronous
- 主从架构读写分离,主库写,从库读
- Elasticsearch ,for scalability
- first: MVC(Model View Controller) design a web —> develop front-end (i.e. html5 css3 javascript jquery vue) + back-end(including database) (some framwork, like Springboot)
设计一个搜索引擎类,去调用已有的各种搜索引擎(比如google、bing等等),对于用户来说输入一些关键词就能得到搜索结果
- 爬取creep:怎么爬取?广度爬取?深度爬取?算法如何打算最优?
- 索引index:索引爬取的数据,得去做去重分析,建立相关数据库,数据库的量也是庞大的
- 收录:怎么确定收录页面的排名?得涉及到相关的排名算法,是以页面内容为导向?外部链接为导向?等等
Stack overflow
whether there is a recursive call
whether there is a large number of cycles or dead cycles
whether there are too many global variables
- Whether the array, List, map data is too large
- Use DDMS tool to find the location of stack overflow
Memory Leak/Leakage
Virtual memory is allocated but not reclaimed when it is no longer needed.
An OutofMemoryError is thrown, but the occurrence of OutofMemoryError does not represent a certain memory leak. It may be caused by improper configuration parameters of the JVM. However, if an exception is thrown after a long time, the risk of a memory leak is very high.
JAVA的内存泄漏(Memory Leak)&内存溢出(Out Of Memory)
Garbage Collection
Garbage collection is used to release space occupied by garbage and prevent memory leaks. This allows efficient use of available memory, cleaning and recycling of objects in the memory heap that have died or haven’t been used for a long time.
Java中可以作为GC Roots的对象包括下面几种:
虚拟机栈(栈帧中的本地变量表)中的引用对象。
方法区中的类静态属性引用的对象。
方法区中的常量引用的对象。
本地方法栈中JNI(Native方法)的引用对象
如何判断是否要回收
引用计数法;给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。—> 简单、高效但是很难处理循环引用,相互引用的两个对象则无法释放。
可达性分析算法(根搜索算法):从GC Roots(每种具体实现对GC Roots有不同的定义)作为起点,向下搜索它们引用的对象,可以生成一棵引用树,树的节点视为可达对象,反之视为不可达。
GC方法
- Mark: reffrence counting and reachability analysis;
- Clean up: sweep (hace fragment, old), copying (no fragment, eden), compact (nofragment, difficult to concurrent)
- Gennerational:(young: coping, old: mark-sweep/compact, permenant: class, const, staticvariable, method)
- CMS: Initial Mark, Concurrent Mark, Remark, Concurrent Sweep
hashmap、hashtable、CurrentHashMap
hashCode
- Integer: 以对应的int值作为hash值
- String:h = 31 * h + val[i];
- Character: ASCII
JVM heap and stack
- 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
- 栈因为是运行单位,因此里面存储的信息都是跟当前线程相关的信息。包括:局部变量、程序运行状态、方法返回值等等;而堆只负责存储对象信息。
算法
几种排序算法
Quick Sort
Concept: Using a pivot point element, partition the array into two sections where everything below the pivot point is smaller and everything above the pivot is larger. The pivot point then moves through the values on the left putting them in order and the then values on the right. This a ‘divide and conquer’ algorithm since it involves making the larger list into smaller lists which are easier to sort.
Time complexity: Average case is O(nlogn).
- Code: The implementation will involve a partition function where you split the list into sub-parts and recursively sort each part. It requires you to pick where the initial pivot point is and how the pivot moves through the list.
- Note: There are plenty of edge cases where it is less successful, but it is usually considered the all around best if you had to guess what to use. You can avoid most worst case scenarios by choosing the pivot wisely (the closest to the median possible).
Merge Sort
- Concept: Split arrays in half to create already sorted single element arrays and merge sorted arrays back together putting everything in the proper order
- Time complexity: O(nlogn). (another advantage:the space complexity of merge sort is good at O(n)
- Code: The implementation utilizes a merge function called again and again to reassemble all elements incorporating them in the correct position.
Insection Sort
- Concept: Iterate over list and place each element in its correct place as you get to it from first to last.
- Code: A while loop inside a for loop can create a process that keeps track of the indices where you can insert the latest element in the correct spot.
- Time complexity: Average is O(n²) and best is O(n)
- Note: Best to use when the list is small and/or almost totally sorted. It takes a long time but it does have some pluses in stability and space. Be sure to mention this as an alternative to the above two sorts if the situation calls for stability/space.
Heap Sort
- Concept: Using a tree based data structure for storing elements in a sorted fashion.
- Code: The implementation uses heapify to make the list into a heap data structure (which is possible to do in array form). And then the second part is manipulating(操作) the elements by taking out the largest (or smallest) elements in order using the information stored in the data structure.
- Time complexity: All cases are O(nlogn).
- Note: It utilized the information stored in the binary tree rather than the information in the list itself to do the sorting, which makes it quicker in edge cases.
Bubble Sort and Selection Sort
- Concept: Bubble goes through list comparing adjacent element pairs and swaps pairs based on value. Selection goes through the list taking out the minimum element and, starting at the beginning, placing them in order.
- Code: Iterate many times over the list incrementing indexes and switching indexes as needed.
- Time complexity: Too long! Average is O(n²) and selection sort’s best case is even O(n²) as well.
- Note: These guys are not efficient and they don’t really have anything going for them to merit their use.
Binary Sort/search Tree
二叉查找树是指一棵空树或者具有下列性质的二叉树:
若任意节点的左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;
任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
任意节点的左、右子树也分别为二叉查找树。
没有键值相等的节点(no duplicate nodes)。二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。为O(log n)。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、Multiset和关联数组等等。
AVL Tree
AVL trees are height balancing binary search tree. AVL tree checks the height of the left and the right sub-trees and assures that the difference is not more than 1. This difference is called the Balance Factor. This allows us to search for an element in the AVL tree in O(log n), where n is the number of elements in the tree.
stack and heap
Stack: static; compile time; LIFO order; memory management automatically; access fast; Know how much data before compile, not too much;
Heap: dynamic; run time; slower; size Is limited on virtual memory; allocate and free at any time